GOAL
This research, led by Dr. Raanan Fattal (HUJI), intends to develop new algorithms for preconditioning linear systems that arise in semi-supervised machine learning algorithms.
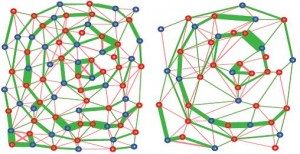
Example of graph coarsening process. Vertices of the graph stand for variables in the graphical model / linear system and the edges stand for statistical dependencies / algebraic relations between variables.
Various basic machine‐learning operations such as maximum‐likelihood and maximum a posteriori estimation, spectral clustering, Markov‐chains and model sampling (Monte‐Carlo methods) boil down to the basic linear algebra operations of solving a linear system and computing its eigen‐decomposition. The matrices involved are typically sparse and can be handled efficiently using sparse data‐structures and iterative solvers. However, as the matrix dimensions grow (larger data-sets) the condition number of the matrix grows and forces the iterative solvers to perform more iteration in order to achieve the same accuracy. This bottleneck introduces a major obstacle in using large models. The team intends to develop new algorithms for preconditioning these matrices, which will bring dramatic speedups for a large variety of machine learning applications operating on large data.
Rather than accelerating matrix‐vector operations, the research aims to reduce the number of iterations needed in the first place when solving linear systems or computing eigen-decompositions. The main concept of this approach is to apply a sequence of matrix coarsening steps which allow the solver to “focus” on different modes of the solution separately and achieve optimal performance. This process is illustrated in the figure on the right.
In the first year the team expects to have various prototype schemes that are applicable to a large family of Gauss‐Markov models. The team will be able to implement various machine learning applications that use and test them, including label propagation in unstructured generalized manifolds and spectral clustering. After the third year, the team will present results from two distinct directions: (i) generalize the construction for a larger family of matrices and models, including non‐quadratic ones by developing a non‐linear procedure. (ii) Collaborate with computer architecture researchers in order to fully identify and define the unique computational pipeline involved in these algorithms. This will consist on a synergy between the algorithmic aspects and the development of hardware requirements.