GOAL
The research team under Prof. Ran Ginosar (Technion) will explore the disruptive implications of such integration and study its impact on both accelerator architecture and machine learning. The goal is to provide insights into the computational and memory structures required for effective integration, what type of machine learning algorithms this tight integration will enable, and how will it affect the design of machine learning algorithms.
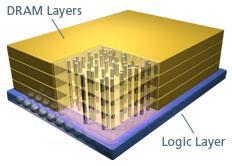
From machine learning perspective, the team plans to design new machine learning algorithms and paradigms matching the novel capability of memory intensive architecture. The goal is to work in the entire spectrum of scale, ranging from small devices that use only few such chips to server and cloud scales composed of several orders of magnitudes more units.
On the applications side, the team will develop robust algorithms that combine modern, machine-learning based image and video analysis techniques with novel efficient lower level image processing operations, in a manner suitable for execution on these novel accelerators.
The first year work consists of analysis of the amount of parallelism in existing code (both sequential and task-based) and developing algorithms that leverage large amounts of memory near the computing unit for various machine learning and image/video applications. In this year the team will analyze hardware/software computing and storage systems that make use of new accelerators so as to enable even the most demanding, I/O-intensive applications to enjoy native performance.
By the third year the team will focus on one or two test cases in machine learning and image/video analysis. The team will develop accelerator algorithms and architectures motivated by them.
- J. Haj-Yihia, Y. Ben-Asher, E. Rotem, “Compiler Assessed CPU Power Management,”, Compiler, Architecture and Tools Conference, sponsored by HiPeac, Haifa , Israel, November 2013
Ran Ginosar ➭
- Leonid Yavits, Amir Morad, and Ran Ginosar. “Computer Architecture With Associative Processor Replacing Last Level Cache and SIMD Accelerator.” IEEE Transactions on Computers, 2013 & 2014
- Leonid Yavits, Amir Morad, and Ran Ginosar. “3-D Cache Hierarchy Optimization”, IEEE 3DIC Conference, 2013.
- L. Yavits, A. Morad, R. Ginosar, “Cache Hierarchy Optimization”, IEEE Computer Architecture Letters, 2013
- Leonid Yavits,, Amir Morad, and Ran Ginosar. “Associative Processor Thermally Enables 3-D Integration of Processing and Memory.” Submitted to IEEE Computer Architecture Letters.
- Leonid Yavits,, Amir Morad, and Ran Ginosar. “Sparse Matrix Multiplication on Associative Processor.” Submitted to IEEE Transactions on Parallel and Distributed Systems.
- T. Morad, L. Yavits, R. Ginosar, U. C. Weiser, “Generalized MultiAmdahl: Optimization of Heterogeneous Multi Accelerator SoC,” IEEE Computer Architecture Letters, 2012
- E. Rotem, R. Ginosar, U. Weiser, A. Mendelson, “Energy-efficient Computing in High Performance Systems”, in: Proceedings of the Fifth International Workshop on Energy-Efficient Design (WEED 2013), held with ISCA-40, June 24th, 2013
- E. Rotem, R. Ginosar, U. C. Weiser, A. Mendelson, ” Power and Thermal Constraints of Modern System on a Chip Computer”, in: Proceedings of the 19th International Workshop on Thermal Investigations of ICs, THERMINIC 2013, September. In addition got accepted for publication in Elsevier Microelectronics Journal.
- E. Rotem, R. Ginosar, U. C. Weiser, A. Mendelson, ” Energy Aware Race to Halt: A Down to EARtH Approach for Platform Energy Management,” IEEE Computer Architecture Letters, vol. 99
- L. Yavits, A. Morad, R. Ginosar, “The Effect of Communication and Synchronization on Amdahl’s Law in Multicore Systems”, Parallel Computing journal, 2014
- A. Morgenshtein, E. G. Friedman, R. Ginosar and “Unified Logical Effort – A Method for Delay Evaluation and Minimization in Logic Paths with RC Interconnect,” IEEE Transactions on Very Large Scale Integration (VLSI) Systems, Vol. 18, No. 5, pp. 689-696, May 2010.
Yuval Cassuto ➭
- O. Rottenstreich, A. Berman, Y. Cassuto and I. Keslassy, Compression for Fixed-Width Memories, ISIT 2013
- Z. Wang, O. Shaked, Y. Cassuto and J. Bruck, Codes for Network Switches, ISIT 2013.
- Y. Cassuto, S. Kvatinsky and E. Yaakobi, Sneak-Path Constraints in Memristor Crossbar Arrays, ISIT 2013
- E. Hemo and Y. Cassuto, Codes for Fast Writes in Multi-Level, NVMs 2014 NVMW – Non-Volatile Memory Workshop
- E. Hemo and Y. Cassuto, Codes for High Performance Write and Read Processes in Multi-Level NVMs, IEEE International Symposium on Information Theory, ISIT 2014
Koby Crammer ➭
Avinoam Kolodny ➭